Download Endpoints
Description of the Resource Download process.
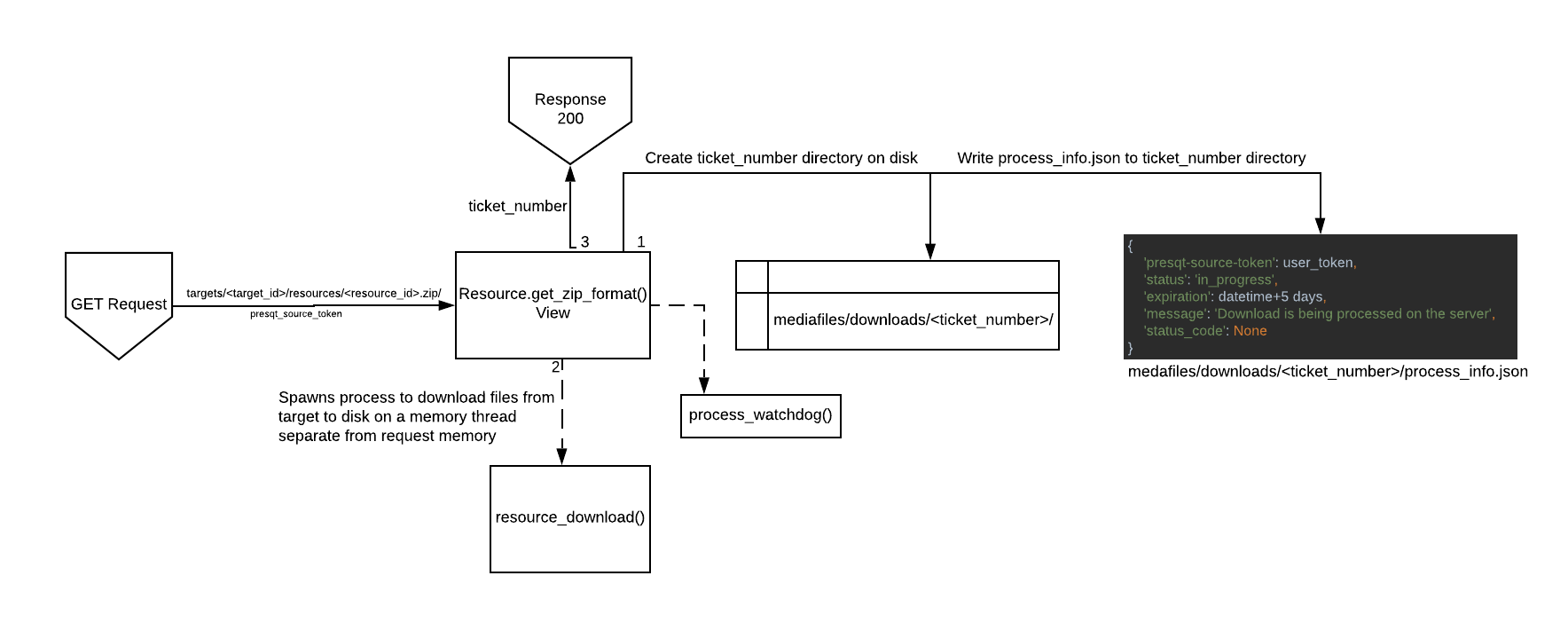
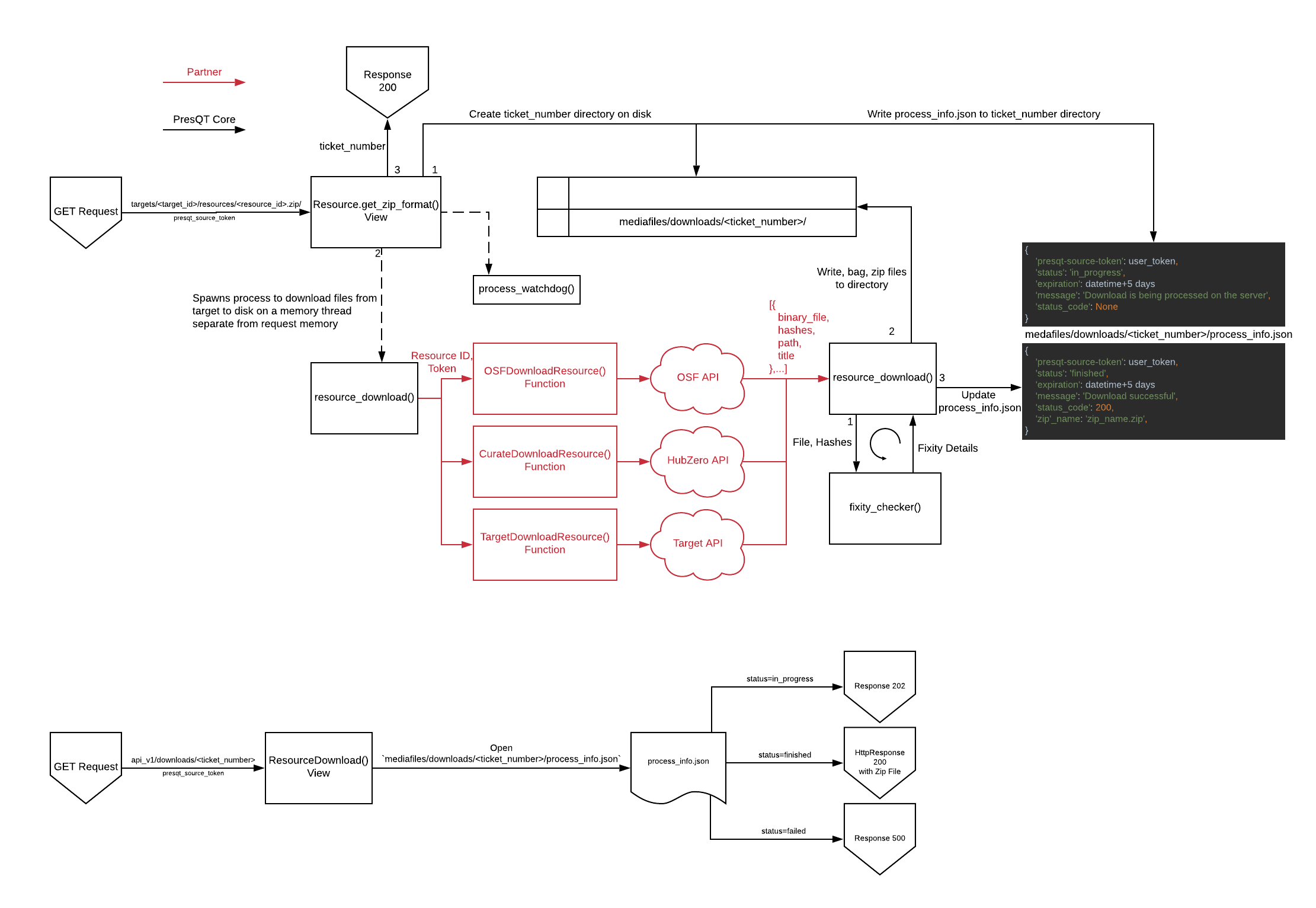
To handle server timeouts, PresQT spawns any resource download off into a separate memory thread from the request memory. It creates a ticket number for a second endpoint to use to check in on the process. The full process can be seen in Image 1. Details of each process can be found below.
Request Memory Process
The /targets/<target_id>/resources/<resource_id>.zip/ GET endpoint prepares the disk for resource downloading by creating a ticket number (UUID) and writing a directory of the same name, mediafiles/downloads/<ticket_number>. In that directory, it creates a process_info.json file which will be the file that keeps track of the download process progress:
The process_info.json file keeps track of various process data but its main use in this process is the 'status' key. It starts with a value of 'in_progress'. This is how we know the server is still processing the download request. So at this point we have a directory that looks like this:
mediafiles
downloads
<ticket_number>
process_info.json
We then spawn the download process off into a different memory thread so it can be completed without a timeout sent back through the request. The spawned off function is _resource_download(). It then returns a 200 response with the ticket number in the payload back to the front end. The full request memory flow can be found below in Image 3.
Server Memory Process
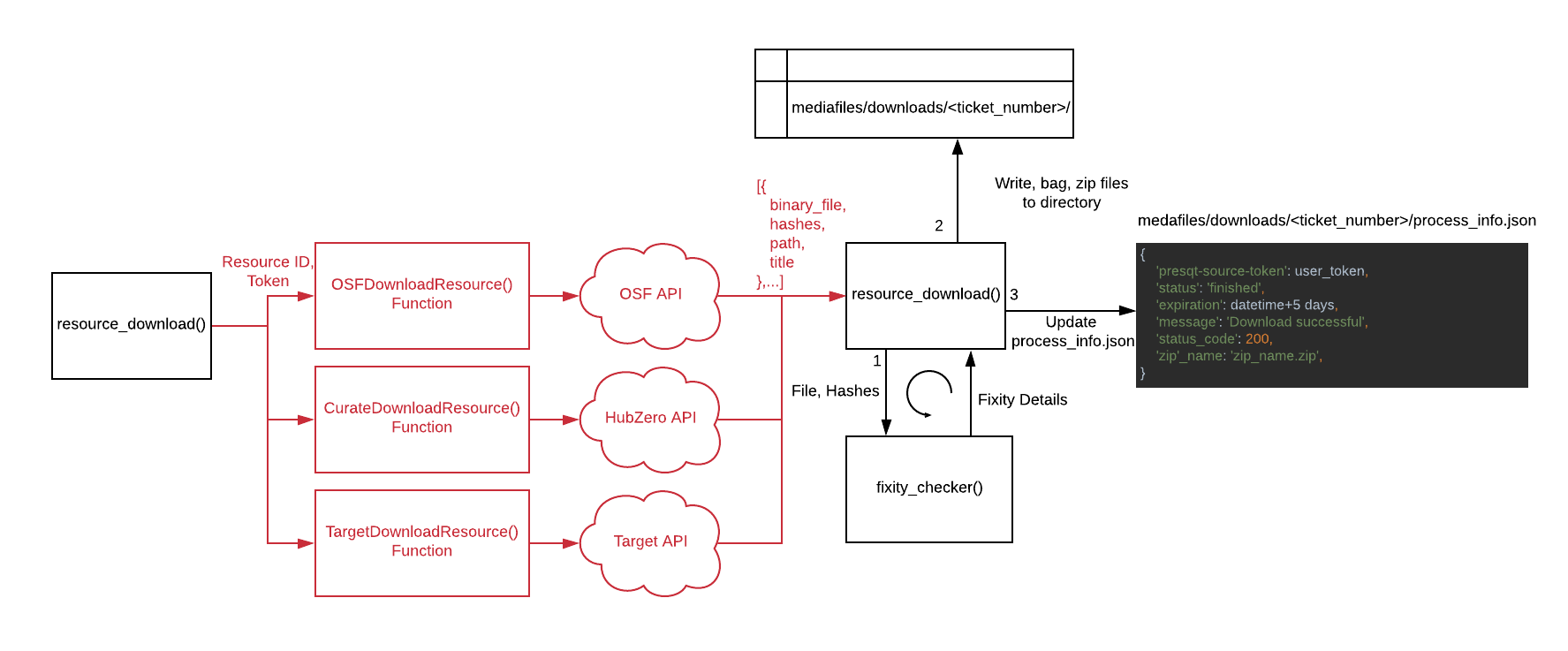
We now have the _resource_download() function running separately on the server. This function will go to the appropriate target download function and fetch the resources we want to download by fetching them from the target API. Once it has the resources it writes them into a new directory named <target_name>_download_<resource_id> located inside of mediafiles/downloads/<ticket_number>. While writing the resource we also run the resources through the fixity checker. Once all resources are written and their fixities checked we write the fixity information to a file called fixity_info.json. So if we are downloading from OSF, with a resource ID of 1234, and a ticket number of 9876 the directory would like the following:
mediafiles
downloads
9876
process_info.json
osf_download_1234
file.jpg
fixity_info.json
We then use BagIt to bag the data:
mediafiles
downloads
9876
process_info.json
osf_download_1234
data
file.jpg
fixity_info.json
bag-info.txt
bagit.txt
We then zip the data contents:
mediafiles
downloads
9876
osf_download_1234.zip
process_info.json
osf_download_1234
data
file.jpg
fixity_info.json
bag-info.txt
bagit.txt
We then update the process_info.json file to reflect that the download process is complete and the zip file is ready for download:
If there was a failure while we downloaded the files from the target then none of the files get written to the disk and the process_info.json file gets updated to reflect the error. For instance, if a bad resource id was given:
The full flow of the resource download in server memory can be found below in Image 5:
Download Job Check-In Endpoint
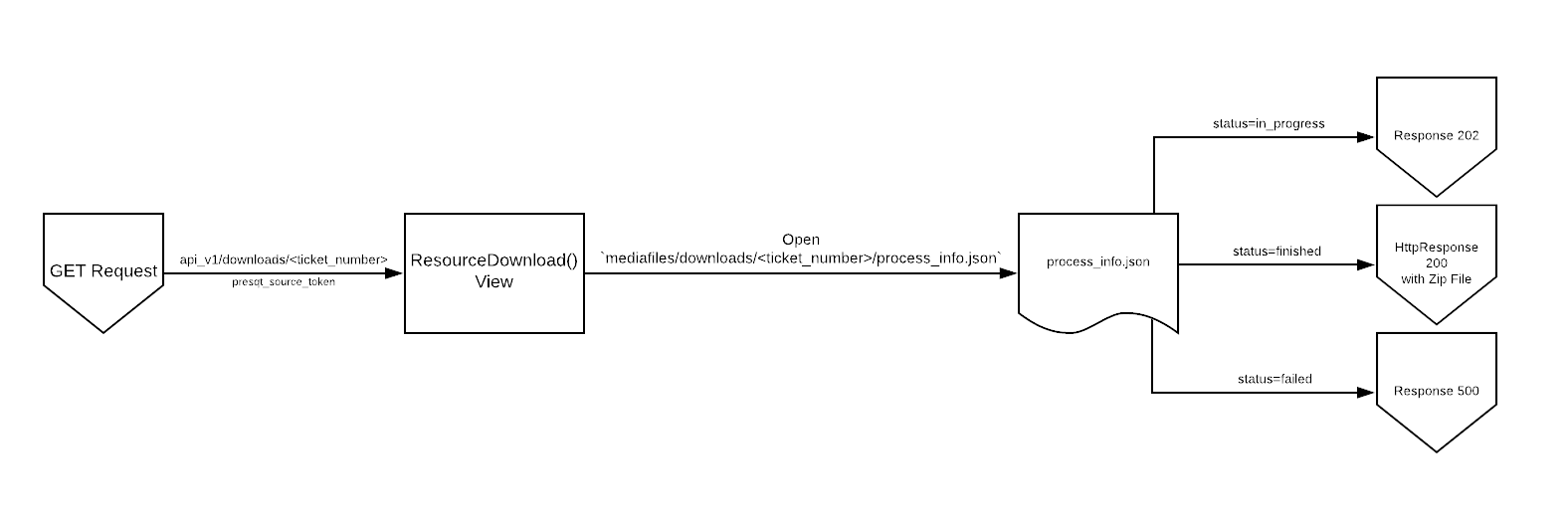
The /download/<ticket_number>/ GET endpoint will check in on the download process on the server to see its status. It uses the ticket_number path parameter to find the process_info.json file in the corresponding folder, mediafiles/downloads/<ticket_number>/process_info.json .
If the status is 'in_progress', it will return a 202 response along with a small payload.
If the status is 'failed', it will return a 500 response along with the failure message and failure error code.
If the status is 'finished', it will return a 200 response along with the zip file found in the same directory.
The full flow for this endpoint can be found on Image 6 below.
Process Watchdog
When downloading, a watchdog function is also spawned away from request memory. The purpose of it is to kill any processes that are taking too long. Right now, we say all downloaded processes have up to an hour to finish before the watchdog will kill the process. If this time limit is hit then after it kills the process the watchdog also updates the process_info.json file to the following:
Download API Endpoints
pageResourcepageDownload Job EndpointsLast updated